把“2026世界杯比分预测更新”做成你的优势:用即时指数与xG模型读懂每一场关键战
比分不是灵感题,而是信息差题。把主流数据平台、即时指数与简单统计模型拼起来,你就能做出更可解释、可复盘的2026世界杯比分预测更新表。

很多人做“2026世界杯比分预测更新”时,习惯从“强队必胜”“状态不错”开始,但真正能提升命中率的,往往是更朴素的一件事:把你看到的新闻、球迷直觉,翻译成一张能解释的表。比分预测不需要玄学,只需要可度量的指标、可持续更新的来源、以及能把指标转成概率的简易模型。
为什么“更新”比“预测”更重要:从赛前72小时到开球前5分钟
世界杯这种高密度赛程里,真正影响比分的变量会在短时间内发生变化:伤停、轮换、阵型、天气、临场态度、甚至赔率与盘口的细微漂移。与其追求一次“神预测”,不如建立一条工作流:把同一场比赛在不同时间点的信号记录下来,让你的判断能随着信息完善而逐步收敛。
- T-72h:基础面(实力、身价、长期表现)
- T-24h:阵容与伤停、旅行与休息天数、首发倾向
- T-2h:首发确认、赔率/指数临场变化、市场情绪
- T-5m:极端因素(突发降雨、临时更换门将等)
数据从哪里来:主流平台 + 即时指数 + 你自己的小表格
你不需要“全网最全”,你需要“稳定、可复查、可对比”。建议分成三层:统计层(比赛事件与球队指标)、指数层(市场对胜平负与进球数的预期)、模型层(把指标转成概率与比分分布)。
1)统计层:控球、xG、射门与防守事件
选择你习惯的平台即可,但要确保能拿到:xG / xGA(预期进球/预期失球)、射门与射正、禁区触球、定位球次数、PPDA或逼抢强度等。核心思路是:比分是结果,xG更接近“过程质量”。
2)指数层:胜平负与大小球的“共识预期”
即时指数(例如欧赔、让球、大小球)本质上是一种“聚合信息”:伤停、首发、资金流向、公众情绪都会被映射到价格里。你要做的不是盲从,而是把指数当作校准器:当你的模型判断与指数长期背离,你需要检查数据、权重、或者是否忽略了关键变量。
3)模型层:大数据模型不是黑箱,你可以学会“借力”
很多平台会给出胜平负概率、进球期望、甚至建议比分。你可以把它们当作第二意见:将其与自己模型输出的“总进球期望”和“胜率”对比,记录差异原因(比如某队对强队时的策略性退守,导致控球高但xG低)。当你持续复盘,模型会越来越“像你”,但更稳。
关键指标怎么读:把“看起来强”拆成能落到比分的变量
控球率:不是越高越好,而是“控球换来了什么”
控球率最容易误导新手。你要搭配两组量一起看:
- 控球 → 终结:控球率 + 场均射门/射正 + 禁区内触球(有没有把球带进危险区)
- 控球 → 防守风险:丢球后被反击的xG(是否“高控球、被一刀”)
经验法则:当一队控球显著高,但xG并不高,常见原因是传控在中后场循环或对手低位防守很成熟。这类比赛更容易出现“1-0、1-1”而非大比分。
xG 与 xGA:用“进攻质量”判断比分上限与下限
xG可以理解为“你创造了多少应该进的机会”。使用时注意三点:
- 看区间,不看单场:至少用最近5–8场(或同级别对手样本)做均值与方差。
- 拆成运动战与定位球:定位球占比高的队伍在淘汰赛更“耐用”,但波动也更大。
- 把xGA当作防线体检:稳定的低xGA往往比“靠门将神扑”的低失球更可信。
场均射门:用“数量 × 质量”纠偏
射门数量能解释比赛节奏,但不能单独决定比分。把它与xG结合成两个衍生指标,特别好用:
- xG/Shot:每次射门的质量(低说明大量远射/勉强起脚)
- Shots Allowed(被射门数)+ xGA:对手打得多但质量低,可能只是“围攻不进”
转会身价:强度基线,而非临场状态
身价更像“资源上限”,能帮助你做跨洲球队比较:阵容深度、单点爆破能力、替补质量。但要避免两个坑:
- 国家队化学反应:高身价不等于高协同,尤其在短周期集训。
- 位置结构:身价集中在前场 vs 集中在后场,会改变比分形态(攻强易大开大合,防强更偏小比分)。
FIFA与俱乐部综合表现:用“谁在高强度环境里被检验过”做修正
FIFA排名或积分可以当作宏观参考,但更有用的是“球员在俱乐部的比赛强度背景”。做一个简单修正项:
- 统计首发潜在球员在顶级联赛/高强度赛事的出场分钟占比(越高,节奏适应越强)
- 关注近期俱乐部表现对国家队战术的影响:例如边后卫是否习惯内收、前锋是否需要大量反击空间
动手搭一个“比分预测表”:用简单统计把信息变成可计算的输出
你只需要一张表(Excel/Sheets都行),核心是把每场比赛转成两个值:主队期望进球 λ_home 与 客队期望进球 λ_away。有了这两个数,就能用泊松分布生成比分概率(0-0、1-0、1-1、2-1……)。
步骤1:计算双方的“基础进攻/防守强度”
用最近N场(建议5–10场,并尽量筛选同级别对手)的均值:
- Attack = xG_for(进攻强度)
- Defense = xG_against(防守风险)
然后用一个朴素的合成方式得到期望进球(示例):
λ_home = BaseGoals × (Home_Attack / Avg_Attack) × (Away_Defense / Avg_Defense) × HomeAdv × Availability
λ_away = BaseGoals × (Away_Attack / Avg_Attack) × (Home_Defense / Avg_Defense) × AwayAdj × Availability
解释一下这些项:
- BaseGoals:赛事整体的平均进球基线(按小组赛/淘汰赛分别设置更合理)
- HomeAdv:主场/近似主场修正(世界杯需按实际场地氛围与旅行距离谨慎设定)
- Availability:可用性系数(核心球员缺阵、轮换、伤愈复出未满状态)
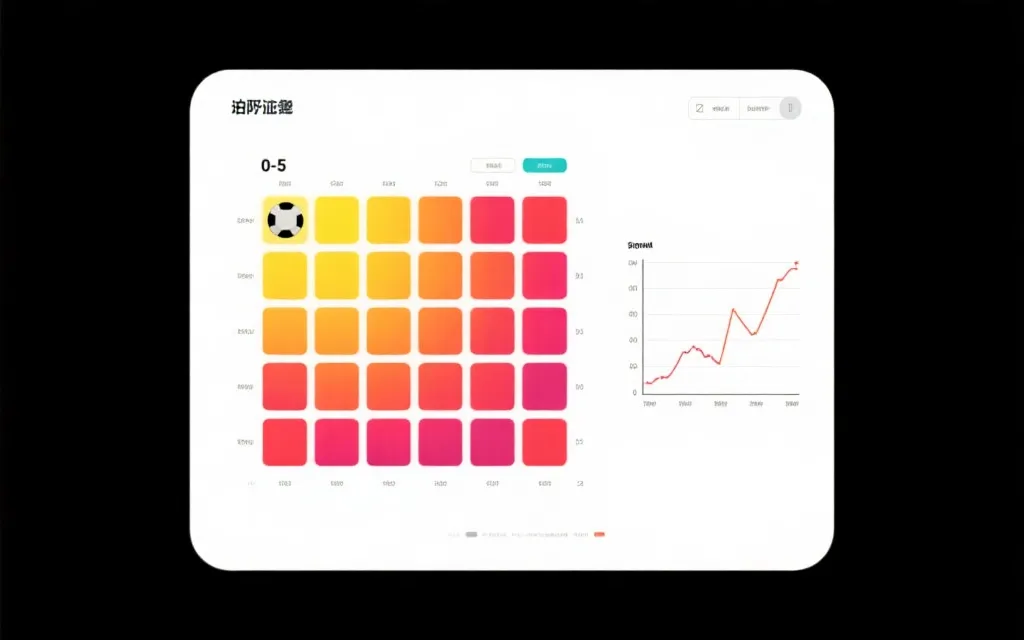
步骤2:用泊松分布生成比分概率(可解释、可复盘)
当你有了 λ_home 与 λ_away,就能得到每个进球数的概率。表格里可以直接用POISSON函数(不同软件函数名略有差异)。你最终会得到一个比分矩阵:行是主队进球0–5,列是客队进球0–5,每个格子是一种比分概率。
步骤3:用即时指数做“校准”,避免模型自嗨
建立两条对照:
- 胜平负概率对照:你的模型输出 vs 指数隐含概率(注意要做简单去水/归一化)
- 大小球对照:你的总进球期望(λ_home + λ_away)与大小球主线是否长期偏离
当偏离出现,先别急着“反向相信指数”。更高效的做法是写下三条检查清单:是否忽略了伤停、是否对手强度样本不匹配、是否淘汰赛策略导致节奏变慢(尤其是强强对话)。
可视化怎么做:让你的判断“一眼就懂”
做预测不仅是为了猜对,也为了让别人愿意相信你。推荐三种轻量可视化(表格里就能完成):
- 雷达图:控球、xG、射门、定位球xG、xGA、逼抢强度,一张图看风格差异。
- 趋势折线:最近8场xG与xGA的滚动均值,看状态是上升还是回落。
- 比分热力表:泊松矩阵高亮前5个最可能比分,并计算“冷门区”合计概率。
每一轮关键比赛的“更新模板”:照着做就能持续迭代
把流程固定下来,你就能稳定产出“2026世界杯比分预测更新”,并且每次更新都有迹可循:
- 建档:记录对阵、开球时间、赛制阶段、预计阵型。
- 拉指标:近N场xG/xGA、射门、定位球、控球与逼抢指标,外加身价与球员强度背景。
- 算λ:输出 λ_home / λ_away 与总进球期望。
- 出矩阵:生成比分概率Top 5,附上胜平负概率。
- 对照指数:记录差异与原因假设(伤停、节奏、对位克制)。
- 赛后复盘:只复盘三个问题——λ是否偏了?偏差来自进攻还是防守?该不该调整权重?
常见误区:你以为在做数据,实际上在做情绪
- 只看比分不看xG:2-0可能是高效率,也可能是低质量机会的偶然。
- 把控球当优势:控球高但推进差,反而更容易被反击“偷一个”。
- 忽视赛制阶段:淘汰赛的风险偏好与小组赛不同,总进球基线应调整。
- 样本混乱:用友谊赛、替补阵容的比赛来估强度,会显著拉偏λ。
结语:预测不是“算命”,而是“让每个结论都有依据”
当你把控球率、xG、射门、身价、FIFA与俱乐部强度背景,以及即时指数放进同一张表里,你会发现比分预测的核心并不神秘:你只是把“感觉”变成了“证据链”。从下一场开始,用你自己的工作流做一次“2026世界杯比分预测更新”,并在赛后认真复盘一次——你会比任何单次押注更接近长期稳定。